A new preview of Seq 3.0 is up on the downloads page. Over last week’s 3.0.19-pre build, this one brings:
- Built-in rowset size caps and
limit nsyntax to override them - Support for scalar transformations like
round()over aggregate operators select *syntax support- An implementation of the
count(distinct())aggregation is nullandis not nulloperators- ~40% faster SQL query execution across the board, and vastly better
likeperformance when searching for prefixes or suffixes - Filtering progress now reports a date in addition to the number of events inspected
- A Clear button to quickly reset the timeline/histogram date range
- Various bug fixes
This preview takes us closer to a general release of 3.0, which we expect to complete by mid-March.
Rather than examine every change in detail (you should download the new build to do that!) this post will take a 1000-ft view of the new build by walking through the experience we expect everyone to have when trying it for the first time.
Download the new build now to follow along...
Done? Okay, so here we are with a fresh Seq 3.0 preview! Let’s try this SQL thing:
select *
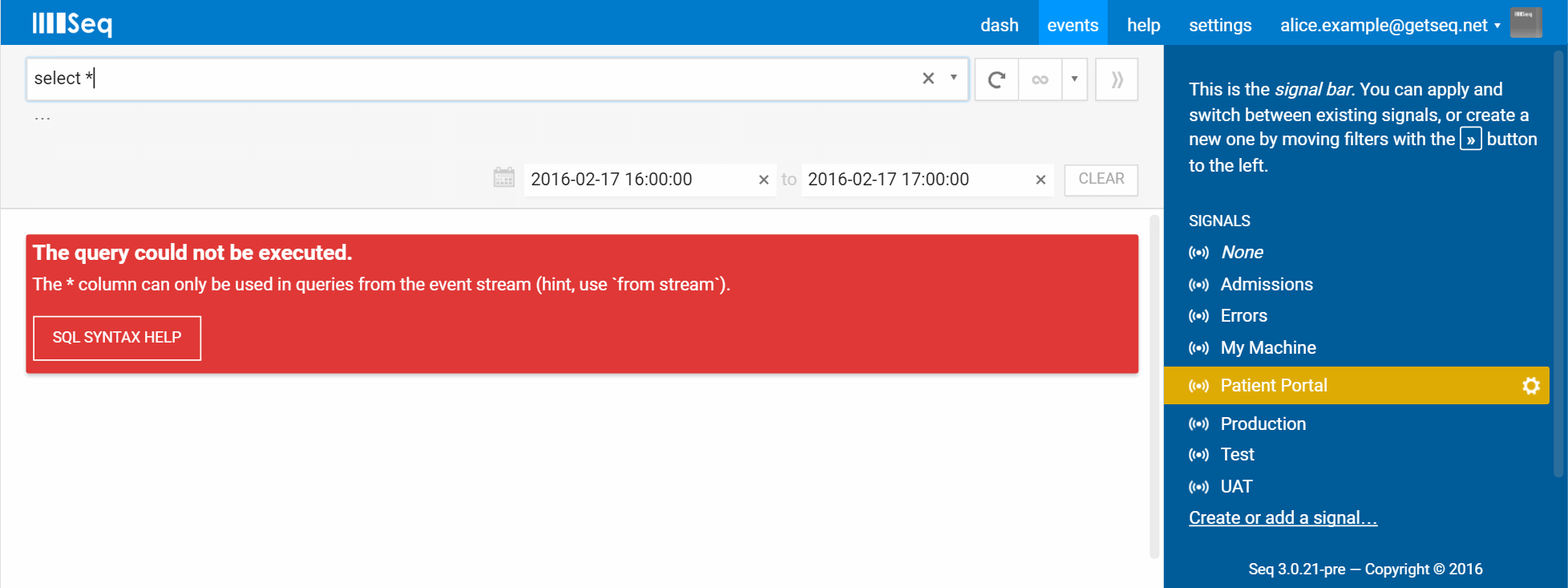
The first query I'll often run when exploring a database is select * from <table>. Since there’s no table per se, select * is a reasonable place to start, but lacks the from stream clause required by Seq.
(We hope you get a feel for the care and attention that have gone into error messages throughout this feature. If you spot an unhelpful one, be sure to let us know!)
Adding from stream like the hint suggests:
select * from stream
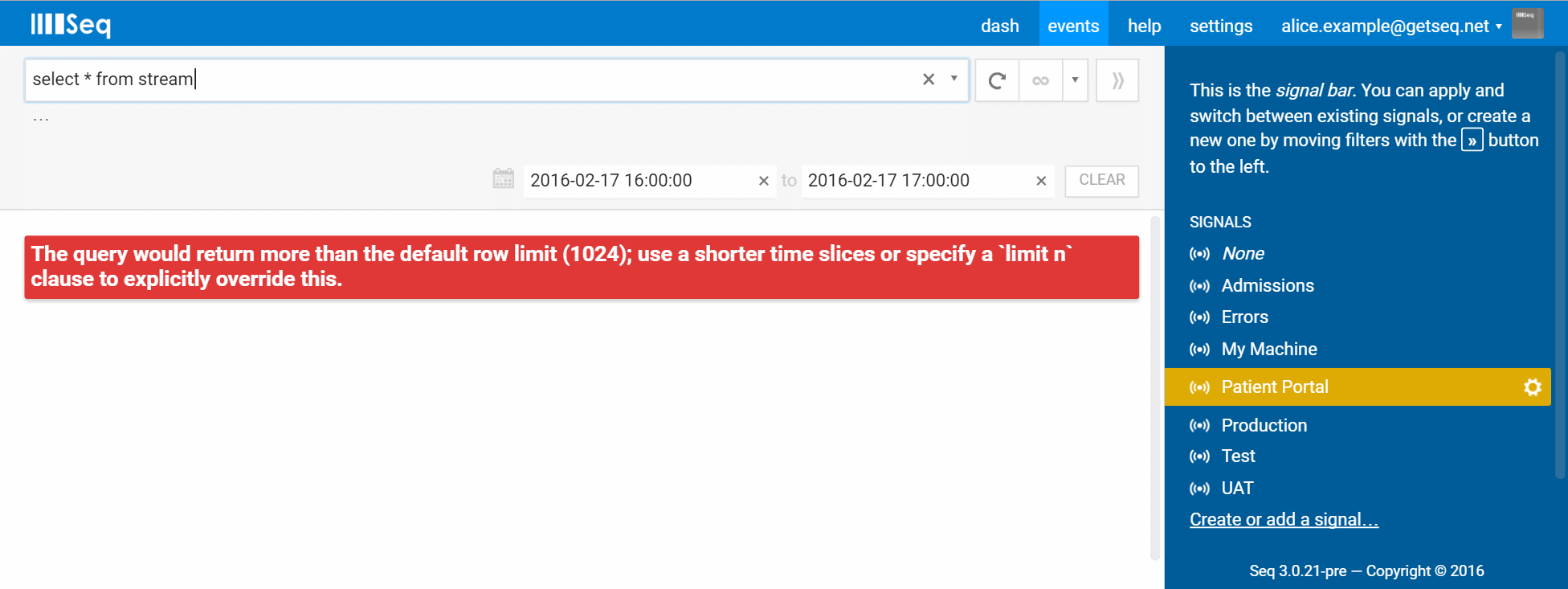
Hmmm, our second attempt to make the same query has also failed, this time because more than 1024 rows would be returned. Given the size of some event streams managed in Seq, it’d be easy to blow up the server and/or browser without some limiting here. Raising an error, rather than silently capping the result set, makes sure that it’s noticed.
Instead of pulling back the entire stream, we’re really only interested in the first few events anyway, so adding limit 10 gets us the results we are expecting:
select * from stream limit 10
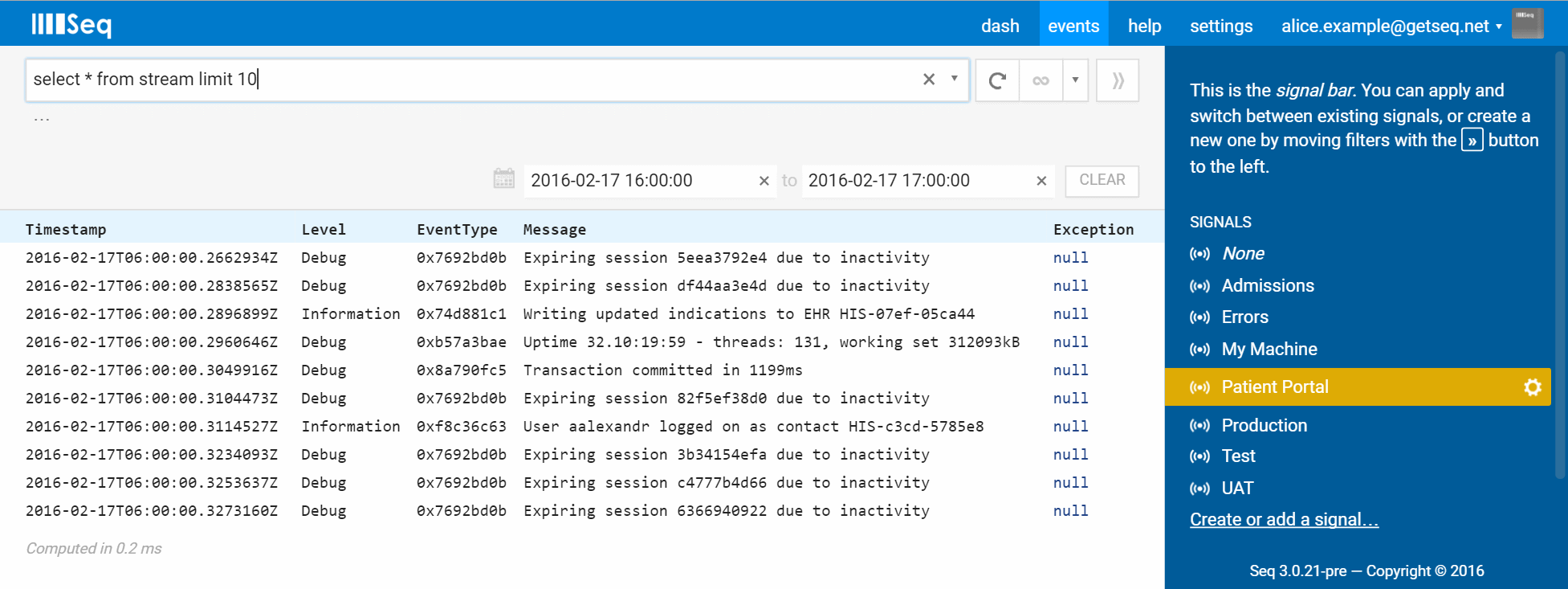
You can see from the columns returned that Seq interprets * as meaning a summary of the fields common to all events, rather than all properties on all events. We could write the same query explicitly as:
select ToIsoString(@Timestamp) as Timestamp,
@Level as Level,
ToHexString(@EventType) as EventType,
@Message as Message,
@Exception as Exception
from stream
limit 10
Now, select * and simple projections aren’t the reason for implementing SQL in Seq, but they’re useful for being able to inspect data without switching back into the regular “event” view and filter syntax.
Once some interesting data are identified, it’s aggregation all the way. Aggregation is how we make sense of large data sets – there might be a thousand requests to a specific API, all with an Elapsed property, so functions like min(), max(), mean() and percentile() reveal properties that are hard to perceive when looking at just the raw values.
select round(mean(Elapsed), 2) as avg_response_time from stream group by time(5m)
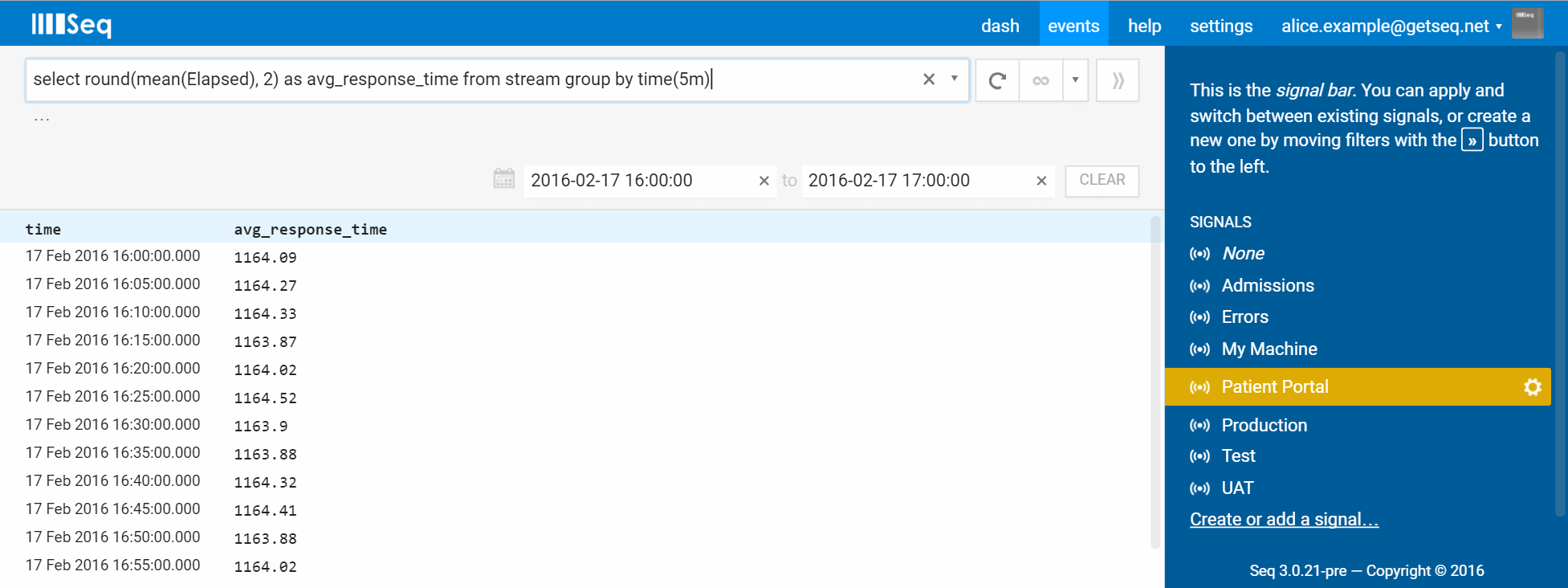
Armed with an stream of log data, there are all kinds of questions about system usage and behavior waiting to be discovered and answered this way.
3.0 expands the diagnostic capabilities of Seq so much that we can’t wait to get it into everyone’s hands. Please help us drive this one to production as fast as possible by downloading the new build and giving your feedback :-)