TL;DR download Seq 3.2 here!
Today we’re pleased to announce that Seq 3.2 is generally available. The bigger items including Snappy compression, filter-based security, and query engine improvements, are highlighted in this announcement. You can find a full changelist at the end of this post.
We try to keep a regular release cadence, if not monthly then close to it. This minimizes the amount of work that’s sitting around, unavailable or in pre-release status, while forward development continues. To get Seq 3.2 into your hands, we had to bump one of the features we’d most looked forward to – an improved SQL editing experience – off into Seq 3.3. If you were looking forward to it too, don’t worry, it’s at the top of the list.
Seq 3.2 is a quick in-place upgrade from any 2.x-3.x version. If you’re upgrading from an earlier Seq version, you’ll need to go via Seq 3.0 first – please don’t hesitate to contact support@getseq.net if you need help or have any concerns.
Snappy compression
Storage bandwidth is limited on many of the less expensive cloud VMs, which has a substantial influence on Seq’s archive search time, as well as warm-up time after a restart.
Seq 3.2 introduces automatic Snappy compression for event data in new extents. Snappy is a fast compression algorithm from Google that provides Seq with good storage space reductions for minimal CPU overhead.
Reducing the footprint of events on disk gives I/O-bound activities a corresponding performance boost. Modest-sized events, which gain the least from compression, still get around 15% space reduction. In normal use, with the occasional large compression-friendly stack trace to chomp down, 30% is a reasonable expectation.
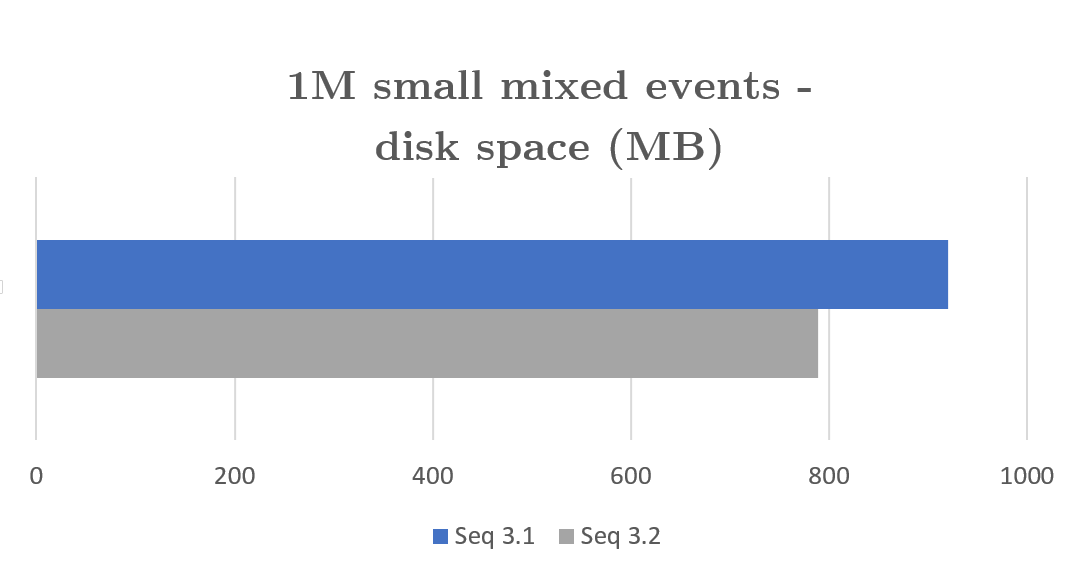
Each extent is a seven-day block of storage on disk, so after an upgrade compression won’t kick in until the current extent is complete an a new one is created – at most, seven days. Existing log data won’t be compressed by the upgrade, so you’ll notice a reduction in the rate of storage growth, rather than a reduction in disk usage, until old uncompressed extents start getting cleaned up by retention policies.
While adding compression we took the opportunity to rework the event serializer to make fewer temporary allocations when pulling events from disk. The improvement in heap fragmentation and data locality after loading a large historical event stream results in an additional query performance boost around the order of 10% in our tests.
Filter-based security
In some organizations, and particularly in agencies, it’s not desirable for everyone on a team to have access to all of the logs in Seq.
Filter-based security is a long-requested addition in Seq 3.2 that permits non-administrative users to view and interact only with events matching a specified filter.
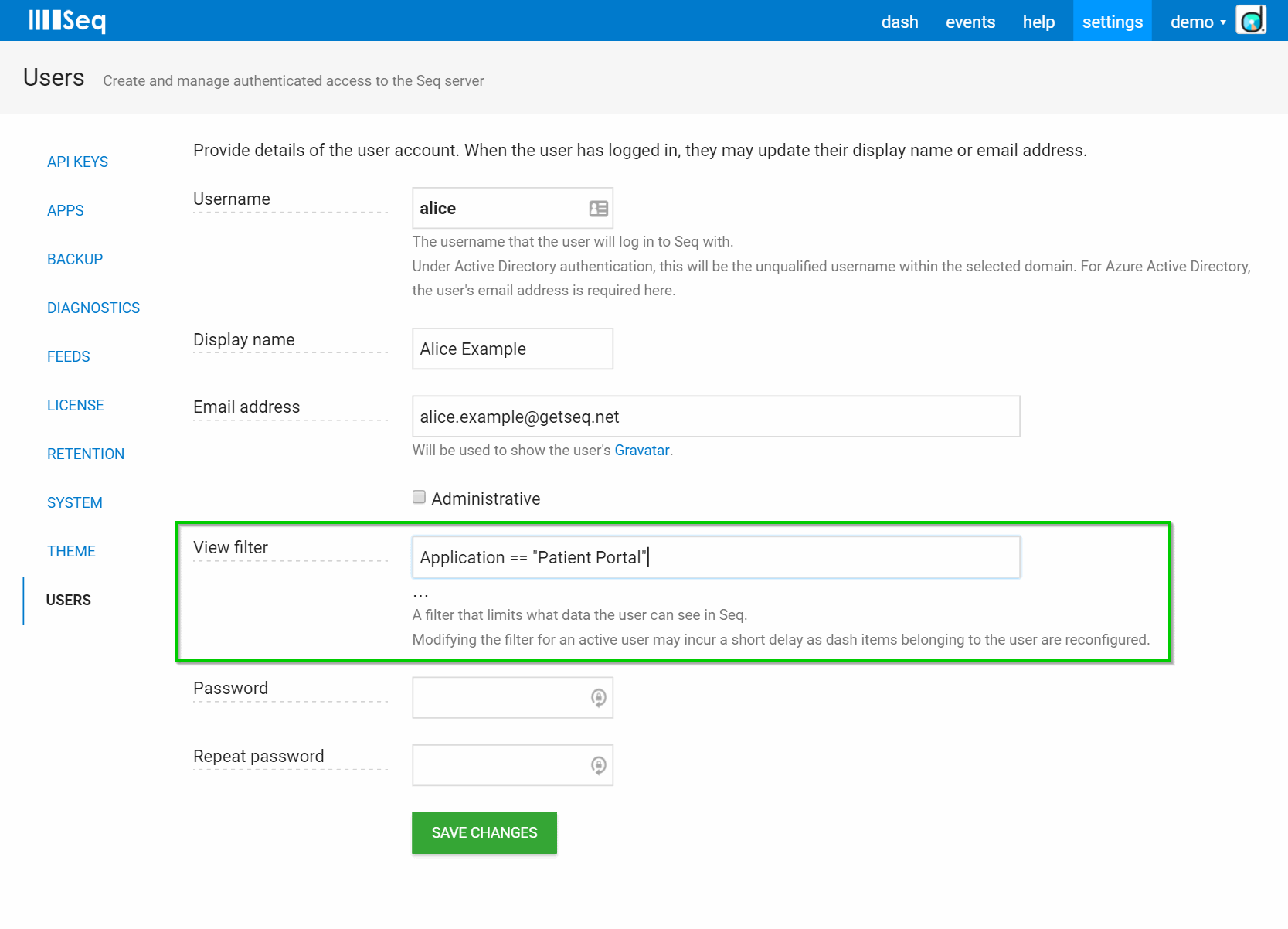
Filter-based security can be paired with API key applied properties to allow groups to only log or view events associated with a particular environment, application, or project.
Query engine improvements
Most interactions with Seq use text search, or filtering based on C#-like Property == "Value" expressions. Since Seq 3.0, SQL is also supported for time-slicing and aggregate operations including count(), max(), distinct() and a host of others.
With each subsequent release, we’ve been improving and extending the SQL engine to enable more data-driven app diagnostics, and that theme continues in 3.2.
SQL language updates
In Seq 3.2:
- Groupings can now be filtered with a
havingclause in conjunction withgroup by - The
order byclause now supports ordering on all result set fields, not only thetimedimension as in earlier releases - Applying
limitto timeseries results now takes fill rows into account, so the returned rows are identical with the top of the non-limited query - The
coalesce()function can be used to control fill in sparse result sets, leading to better chart output - New aggregate
any()andall()can be used to test groups for Boolean properties
The last one is a nifty little “extension” to normal SQL semantics that is convenient for diagnostics in particular, and warrants a brief example.
Information is logged piecemeal as software executes. For example, one piece of code may log whether or not a cached result could be used when processing a web request. A later piece of code might log the time taken to complete the request:
12:30:09.223 [INF] Using cached results
…
12:30:09.229 [INF] Completed request in 400 ms
It’s easy to find all requests that used cached results, by searching based on the event type of the first event and examining the attached RequestId property. In a filter this might look like $12345678 or in a SQL where clause the syntax is where @EventType = 0x12345678.
It’s also easy to find requests that took over 100 ms by filtering on the Elapsed property, for example Elapsed > 100.
Connecting these two pieces of data isn’t trivial though. How do you find the requests that both used cached results, and took more than 100 ms to execute?
In SQL this is the domain of joins or subqueries, but these SQL features aren’t on the table for inclusion in this release. Besides, both seem a bit heavyweight to be comfortable in the flow of an average debugging session.
The answer, in Seq 3.2, is the any() aggregate. This aggregate function accepts a Boolean argument, and returns true if any of the elements within a group are true.
We can test if any event in a request was Using cached results, and also whether any event logged a response time above 100 ms.
select any(@EventType = 0x12345678) as cached,
any(Elapsed > 100) as slow
from stream
group by RequestId
having cached and slow
The having clause lets us pick out only the requests where both of the conditions are true.
Query execution improvements
Under the hood, limits and resource constraints have been completely reworked. Among other improvements, instead of relying on limit to prevent runaway queries a timeout and cancellation mechanism will kick in at 60 seconds to terminate any (probably accidental) queries attempting to “aggregate the world”. If the default timeout is too short for the kinds of queries you happen to run, it can be bumped up in your per-user preferences. Memory limits have also been overhauled, but these should pretty much always stay out of your way.
Datalust
Last but not least, you may have noticed our company re-brand going on behind the scenes over the last month or so. We’re pleased to announce that Continuous IT Pty Ltd is now Datalust, a name that better reflects our values, the product we build, and what we bring our customers.
Release notes for Seq 3.2.16
The 3.1.6 milestone includes the following changes since Seq 3.1.
- SQL queries : LIKE doesn't return messages with matching text when message has several lines (#430)
any(),all()as aggregate operators (#427)- Accept non-Serilog levels enhancement (#424)
- Optimized storage reader (#423)
- Snappy compression (#422)
- Extend
ORDER BYto more scenarios (#420) - 'Help' message not shown when timeseries view is selected for some result sets (#418)
HAVINGin SQL queries (#416)- SQL queries/charting: handling missing values (#412)
- Tag order not respected when output (#411)
- Include the selected view (table/timeseries/bar) in the URL (#410)
- Azure Active Directory reply URL should always be derived from the client's requested URL (#409)
- Unhandled exception during service stop attempt: The extent is temporarily offline (#408)
- Grant users access to a view/filtered event stream (#155)