Seq is a log server that's built using a few programming languages; we have a storage engine called Flare written in Rust, and a server application written in C#. Our language stack is something I've talked about previously.
Between Rust and C# we have a foreign function interface (FFI) that lets us call out to Rust code from within the .NET runtime. In this post I'd like to explore our approach to FFI between Seq and its storage engine using the API for reading log events as a reference.
To give you an idea of what the reader API looks like, here's an example of how it can be used in C# to enumerate over all events in the storage engine in order:
IEnumerable<(Key, byte[])> ReadAllEvents(Store store)
{
var range = new Range(Bound.Unbounded, Bound.Unbounded);
var order = Ordering.Ascending;
// Begin a reader over the entire store
// Events will be yielded oldest first
// The `BeginRead` method calls Rust code
using (var reader = store.BeginRead(range, ordering))
{
// Create a buffer to read the event into
// This could be leased from a pool instead
var readInto = new byte[1024];
// The `TryReadNext` method calls Rust code
ReadResult read;
while (!(read = reader.TryReadNext(readInto.AsSpan())).IsDone)
{
// If the buffer is too small, resize it and read again
if (read.IsBufferTooSmall(out var required))
{
readInto = new byte[required];
continue;
}
// Get the contents of the event from the result
read.GetData(out var key, out var payload);
yield return (key, payload.ToArray());
}
}
}
In the above example, the store.BeginRead and reader.TryReadNext methods are implemented in Rust. If any of that Rust code panics or returns an error then we capture them within .NET exceptions like this:
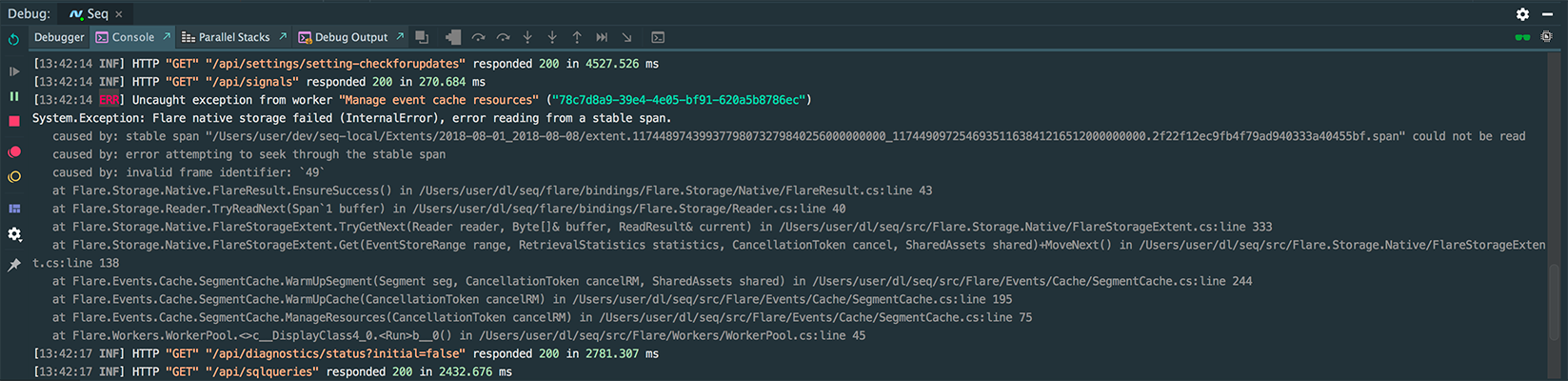
The caused by lines are the trace we get from Rust, which tells us that it ran into a data corruption trying to read an event from disk.
The main components of Seq's storage engine FFI that we'll be exploring are:
- The high-level C# class
Reader. In the above example, the call tostore.BeginReadreturns aReader. - The handles
FlareReaderHandlein Rust and its C# counterpartReaderHandle. These live a layer below theReader. - The binding functions. These perform actions on the handles. There are three involved in reading events:
flare_read_begin: Begin a read transaction, which has a time range to read from and direction to read in.flare_read_next: Read the next event into a caller-supplied buffer.flare_read_end: Finish the read transaction and clean up its resources.
- The infrastructure for capturing and surfacing Rust errors and panics as .NET exceptions.
The benefits and drawbacks of FFI
Building software in multiple languages allows different components to be implemented in particularly idiomatic ways, but integrating those components can be challenging. The challenge comes from Rust and C# both being safe languages, but only being able to talk to each other by pretending to be unsafe C. That means within the FFI itself we can't just rely on Rust's ownership system or .NET's garbage collector to guarantee referenced data is valid without some extra help. Contracts built up in one language aren't guaranteed to be enforced by the other. Mistakes in this unsafe interface are prime suspects for invoking undefined behavior so we have to design it carefully.
There are other constraints in the FFI in addition to its unsafe nature. We can only share certain kinds of values across the boundary, like primitive numbers, pointers, and simple datastructures. Specifically on the Rust side, we also have to deal with potentially null values, which aren't a feature of safe Rust code.
All things considered though, the surface area of the FFI is small compared to the codebases on either side of it. If we were going to tackle building a storage engine entirely in C# we'd need a liberal sprinkling of unsafe throughout the whole codebase. Having said that, the recent focus on lower-level features in C# 7 is starting to make it feel more idiomatic to write performance-sensitive code in C# without losing all notion of safety. We'll see some of those features at work in the C# side of our FFI later. All in all, we're happy to trade some design challenges in the FFI for access to Rust's safety and performance characteristics and ecosystem within the rest of the storage engine codebase, and to keep our C# app code within Seq itself productive.
With a little background behind us, let's dive straight into some code and look at the way state is managed between Rust and C#.
Handles
Rust and C# have different fundamental approaches to managing memory safely. Neither of these are available to us when sharing state between them in the FFI, because Rust doesn't understand C#'s garbage collector and C# doesn't understand Rust's ownership system. So to help us manage shared state safely we wrap raw pointers to its memory in handles. These handles carry additional semantics over the raw pointers to prevent unsafe behaviour at runtime. Each handle has a definition in Rust and a corresponding pair in C#.
Let's look at the Rust side first.
In Rust
The handles in Rust are responsible for allocating and deallocating shared FFI state in Rust's heap. The handle for a reader looks like this:
/**
An opaque handle to a `StoreReader`.
The reader is not safe to send across threads or access concurrently.
*/
pub struct FlareReader {
inner: StoreReader,
}
pub type FlareReaderHandle = HandleOwned<FlareReader>;
Where StoreReader is the more idiomatic Rust type for reading from a Flare store that the handle is wrapping. We'll see it at work later.
Safe mutable handles with HandleOwned
There's not much to see in the FlareReader, because it just wraps StoreReader, and the meat of the FlareReaderHandle itself is in that generic HandleOwned type. So let's look at HandleOwned in more detail. Don't worry too much about the Send and UnwindSafe traits yet, I'll explain what they're all about in a moment. HandleOwned looks like this:
/**
A non-shared handle that cannot be accessed by multiple threads.
The handle is bound to the thread that it was created on.
The interior value can be treated like `&mut T`.
*/
#[repr(transparent)]
pub struct HandleOwned<T>(*mut ThreadBound<T>) where T: ?Sized;
unsafe_impl!(
"The handle is semantically `&mut T`" =>
impl<T> Send for HandleOwned<T>
where
T: ?Sized + Send
{
}
);
impl<T> UnwindSafe for HandleOwned<T>
where
T: ?Sized + RefUnwindSafe
{
}
impl<T> HandleOwned<T>
where
T: Send + 'static
{
fn alloc(value: T) -> Self {
let v = Box::new(ThreadBound::new(value));
HandleOwned(Box::into_raw(v))
}
}
impl<T> HandleOwned<T>
where
T: ?Sized + Send
{
unsafe_fn!("There are no other live references and the handle won't be used again" =>
fn dealloc<R>(handle: Self, f: impl FnOnce(&mut T) -> R) -> R {
let mut v = Box::from_raw(handle.0);
f(&mut **v)
}
);
}
impl<T> Deref for HandleOwned<T>
where
T: ?Sized
{
type Target = T;
fn deref(&self) -> &T {
unsafe_block!("We own the interior value" => {
&**self.0
})
}
}
impl<T> DerefMut for HandleOwned<T>
where
T: ?Sized
{
fn deref_mut(&mut self) -> &mut T {
unsafe_block!("We own the interior value" => {
&mut **self.0
})
}
}
HandleOwned is an opaque wrapper over a *mut T, which is a raw pointer. HandleOwned is solely responsible for allocating, deallocating, and dereferencing the memory behind that pointer. It's not accessed in C#. We try to communicate the handle's safety contract using a few standard Rust traits. This contract is actually lost across the FFI boundary so we need a few safety nets at runtime to catch ourselves if we violate it. It's still worth having the traits appropriately implemented though even if they alone can't force the foreign C# code to use the handle correctly. Their presence serves as documentation for the way we expect the handles to be used. Let's look at these traits in some more detail now.
Maintaining thread safety
Thread safety is a property of mutli-threaded code that only accesses shared state in a synchronized way that's free from potential data races (there are actually some additional requirements around dangling pointers that we'll deal with later).
Rust has a pair of traits for communicating thread safety; Send and Sync. Together, they form a framework for concurrency that allows Rust code to share state when it's safe, but prevent it when it's not. The Send trait tells us whether a value can safely be sent to different threads. The Sync trait tells us whether a value can safely be accessed from different threads.
The difference between Send and Sync can be a bit subtle. I think a helpful example of how they work together comes from an impl block in the standard library that looks a little like this:
impl<'a, T> Send for &'a T where T: Sync { }
It tells us that a borrowed reference, &'a T, is safe to send across threads if the data it references, T, is safe to access from different threads.
Rust will automatically try and implement Send and Sync for a type, so long as its contents are Send and Sync. This is usually achieved through standard library abstractions like Arc for thread-safe reference counting, and Mutex for thread-safe mutability.
For HandleOwned, we simply don't want multiple threads to get a hold of the handle because we treat it like a mutable reference, and in Rust having multiple live mutable references to the same data is not allowed. There are a few complications though, Send and Sync are compile-time contracts that only Rust understands. There's nothing stopping a foreign caller from copying a HandleOwned into multiple threads and attempting to access the contents concurrently. As a safety net, HandleOwned wraps its contents in a ThreadBound type when allocating it. ThreadBound is similar to the fragile::Fragile type in the ecosystem in that it panics if it's dereferenced from a different thread than the one it was created on. This check effectively also enforces !Sync at runtime by catching cases where the handle has been passed to a different thread.
There's an important exception to binding HandleOwned to its initial thread though; in .NET resources aren't guaranteed to be reclaimed from the same thread that allocated them. That means we need to be able to logically Send the HandleOwned to another thread so the GC can finalize it. So our HandleOwned implements the Send trait so long as its contents do. That way it's safe to deallocate it from a finalization thread.
Maintaining unwind safety
Unwind safety in Rust is like exception safety in C#. It's a property of code that guarantees that broken invariants aren't observable if a function panics and breaks normal control flow.
Rust has a pair of traits (Rust seems to have a lot of systems that are built up from a pair of traits) for communicating unwind safety; UnwindSafe and RefUnwindSafe. The UnwindSafe trait tells us whether an owned value is unwind safe. The RefUnwindSafe trait tells us whether a borrowed reference to a value is unwind safe.
To demonstrate the difference between UnwindSafe and RefUnwindSafe, let's turn to some more impl blocks in the standard library:
impl<'a, T> UnwindSafe for &'a T where T: RefUnwindSafe { }
impl<T> UnwindSafe for Rc<T> where T: RefUnwindSafe { }
impl<T> UnwindSafe for Arc<T> where T: RefUnwindSafe { }
These blocks tell us that some reference to a type, T, is unwind safe if T is unwind safe while it's borrowed. RefUnwindSafe lets us be abstract over the kind of reference to T that we're dealing when, whether it's &'a T, Rc<T>, Arc<T>, or in our case, HandleOwned<T>.
Rust considers everything unwind safe by default unless it can be mutated:
impl<'a, T> !UnwindSafe for &'a mut T { }
Some types guarantee unwind safety by poisoning their state on a panic. The standard library's Mutex works this way. After being poisoned that state is no longer accessible. It's a broadly applicable technique for guaranteeing unwind safety regardless of how the state itself is mutated. Many types in the storage engine use poisoning to guarantee unwind safety in case something unexpected happens, like a write to disk fails.
Ensuring references remain valid
Rust uses a type system to try and prove a program only accesses its memory in valid ways. These types are called lifetimes (they're the little 'a sigils in the &'a T). When defining FFI handles in Rust we need to be careful with these lifetimes because, following the theme of Send and Sync, they're a compile-time contract with other Rust code. C# doesn't understand this contract so for data that's shared across the FFI boundary we can't just depend on lifetimes to ensure references to other pieces of state remain valid. Instead we depend on runtime reference counting using Rc<T> or Arc<T>. That's why HandleOwned has a 'static requirement in its definition. 'static is a special lifetime for data that can live for as long as the program itself. That means if T: 'static, then T is probably an owned value or a reference to static data compiled into the program itself. HandleOwned will only accept data that can live until we're ready to deallocate it.
Right now, handles are just wrappers over a raw pointer. This means there's nothing technically stopping a foreign caller from re-using that handle after it's been freed. At some point in the future we could turn those raw pointers into entries in some global handle table. That table could then detect attempts to access a handle that's already been freed.
Safe concurrent handles with HandleShared
Having HandleOwned bound to a single thread makes it possible for us to ensure there's only a single live mutable reference to its state. That means thread-safety is achieved by simply forbidding multiple threads from using the handle. That's nice, but a bit limiting for potentially long-lived handles so we have a complement to HandleOwned called HandleShared that's safe for concurrent access, so long as its contents are. It looks like this:
/**
A shared handle that can be accessed concurrently by multiple threads.
The interior value can be treated like `&T`.
*/
#[repr(transparent)]
pub struct HandleShared<T: ?Sized>(*const T);
unsafe_impl!(
"The handle is semantically `&T`" =>
impl<T> Send for HandleShared<T>
where T: ?Sized + Sync
{
}
);
impl<T> UnwindSafe for HandleShared<T>
where
T: ?Sized + RefUnwindSafe
{
}
impl<T> HandleShared<T>
where
T: Send + Sync + 'static
{
fn alloc(value: T) -> Self {
let v = Box::new(value);
HandleShared(Box::into_raw(v))
}
}
impl<T> HandleShared<T>
where
T: ?Sized + Send + Sync
{
unsafe_fn!(
"There are no other live references and the handle won't be used again" =>
fn dealloc<R>(handle: Self, f: impl FnOnce(&mut T) -> R) -> R {
let mut v = Box::from_raw(handle.0 as *mut T);
f(&mut *v)
}
);
}
impl<T> Deref for HandleShared<T>
where
T: ?Sized
{
type Target = T;
fn deref(&self) -> &T {
unsafe_block!("We own the interior value" => {
&*self.0
})
}
}
An example of a HandleShared is StoreHandle, which holds most of the state for an instance of the storage engine and is safe for concurrent access:
/**
An opaque handle to a `Store`.
The store is safe to send across threads and access concurrently.
*/
pub struct FlareStore {
inner: Store,
}
pub type FlareStoreHandle = HandleShared<FlareStore>;
The StoreReader type we saw before borrows a lot of state from the Store.
In C#
Memory in C# is managed by a garbage collector in the .NET runtime. It takes care of keeping objects alive for as long as their accessible, and reclaiming their memory when they’re not. Rust doesn't know about the .NET garbage collector though, so from .NET's point of view Rust is unmanaged code. There are a lot of subtle design challenges that can lead to nasty memory safety issues when integrating managed and unmanaged code. Fortunately though, this is all very well-trodden territory and we have plenty of tools at our disposal in .NET to manage the complexity of building safe, managed APIs to unmanaged resources. We'll see some of these tools in action shortly.
Let's start by looking at the Reader class, which is the high-level C# API for reading events from the Rust storage engine. It looks like this:
public sealed class Reader : IDisposable
{
readonly ReaderHandle _handle;
internal Reader(ReaderHandle handle)
{
_handle = handle;
}
public ReadResult TryReadNext(Span<byte> buffer)
{
EnsureOpen();
unsafe
{
fixed (byte* bufferPtr = buffer)
{
var result = Bindings.flare_read_next(
_handle,
out var key,
(IntPtr)bufferPtr,
(UIntPtr)buffer.Length,
out var actualValueLength);
if (result.IsBufferTooSmall())
{
return ReadResult.BufferTooSmall((int)actualValueLength);
}
if (result.IsDone())
{
return ReadResult.Done();
}
result.EnsureSuccess();
return ReadResult.Data(key, buffer.Slice(0, (int)actualValueLength));
}
}
}
public void Dispose()
{
_handle.Close();
}
void EnsureOpen()
{
// Invalid handles will still be caught by the unmanaged bindings
// This method just surfaces a more accurate exception
if (_handle.IsClosed)
throw new ObjectDisposedException(
nameof(Reader),
"The reader has been disposed."
);
}
}
The call to Bindings.flare_read_next is executing Rust code on the FlareReaderHandle we saw earlier. We'll look at the exact definition of flare_read_next a bit later.
Safe arbitrary memory, without allocating
The Reader.TryReadNext method returns a type called ReadResult that carries the result of reading the event into a buffer, along with the event's byte payload. ReadResult is a ref struct, which is a new C# 7 feature to guarantee instances can never be boxed on the heap. That means a ref struct has a well-defined lifetime that's tied to a specific stack frame. This is what it looks like:
public ref struct ReadResult
{
Key _key;
Span<byte> _value;
int _requiredLength;
Result _result;
enum Result
{
Ok,
Done,
BufferTooSmall
}
internal static ReadResult Data(Key key, Span<byte> value)
{
return new ReadResult
{
_key = key,
_value = value,
_result = Result.Ok
};
}
internal static ReadResult Done()
{
return new ReadResult
{
_result = Result.Done
};
}
internal static ReadResult BufferTooSmall(int requiredLength)
{
return new ReadResult
{
_requiredLength = requiredLength,
_result = Result.BufferTooSmall
};
}
public bool IsBufferTooSmall(out int required)
{
if (_result != Result.BufferTooSmall)
{
required = 0;
return false;
}
required = _requiredLength;
return true;
}
public bool IsDone => _result == Result.Done;
public bool HasValue => _result == Result.Ok;
public void GetData(out Key key, out Span<byte> value)
{
if (!HasValue)
throw new InvalidOperationException($"`{nameof(ReadResult)}` has no data.");
key = _key;
value = _value;
}
}
The payload field is a Span<byte> which itself is a ref struct that acts like a potentially GC-aware pointer to arbitrary memory.
The effort so far in C# 7 to improve the semantics and safety of working with arbitrary memory, and for working with value types in general, makes the .NET side of the FFI easier to build safely with very little overhead.
Managing unmanaged resources with SafeHandle
In the Rust FFI handles, we have a fundamental HandleOwned type that encapsulates the memory safety requirements that the consuming Rust code expects to be maintained. We have a similarly fundamental handle type behind Reader in C# called ReaderHandle. It looks like this:
class ReaderHandle : SafeHandle
{
public ReaderHandle()
: base(IntPtr.Zero, true)
{
}
[ReliabilityContract(Consistency.WillNotCorruptState, Cer.MayFail)]
protected override bool ReleaseHandle()
{
if (handle == IntPtr.Zero) return true;
var h = handle;
handle = IntPtr.Zero;
return Bindings.flare_read_end(h).IsSuccess();
}
public override bool IsInvalid => handle == IntPtr.Zero;
}
ReaderHandle is a class that is responsible for integrating with the .NET garbage collector by inheriting from the SafeHandle class. SafeHandle takes care of a lot of the subtlety of acquiring and releasing unmanaged resources safely. It wraps a raw pointer and ensures the contents of the ReleaseHandle method will get called in a constrained execution region during finalization if the handle isn't released sooner. That means that one way or another, when the handle is no longer accessible the unmanaged resources it wraps will have a chance to get reclaimed.
Indicating success or failure
When making FFI calls, we want to be able to capture normal errors in Rust and make them available to the foreign caller. In Seq, we also want to catch any potential panics from the storage engine (even though we don’t expect them under normal operation) so we have a chance to log them before either shutting down or attempting to recover. FFI error management is provided by the FlareResult type, which has both a Rust and a C# implementation.
In Rust
FlareResult is an enum for returning a simple status code across an FFI boundary that follows a standard pattern for making more detailed error information available to the foreign caller.
FlareResult looks something like this:
/** A container for the last result type returned by an FFI call on a given thread. */
thread_local! {
static LAST_RESULT: RefCell<Option<LastResult>> = RefCell::new(None);
}
struct LastResult {
value: FlareResult,
err: Option<String>,
}
/**
An indicator of success or failure in an FFI call.
If the result is not success, a descriptive error stack can be obtained.
*/
#[repr(u32)]
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
enum FlareResult {
Ok,
Done,
BufferTooSmall,
ArgumentNull,
InternalError,
..
}
impl FlareResult {
/**
Attempt to get a human-readable error message for a result.
If the result is successful then this method returns `None`.
*/
fn as_err(&self) -> Option<&'static str> {
match *self {
FlareResult::Ok | FlareResult::Done => None,
FlareResult::ArgumentNull => Some("a required argument was null"),
FlareResult::BufferTooSmall => Some("a supplied buffer was too small"),
FlareResult::InternalError => Some("an internal error occurred"),
..
}
}
/**
Call a function that returns a `FlareResult`, setting the thread-local last result.
This method will also catch panics, so the function to call must be unwind safe.
*/
pub(super) fn catch(f: impl FnOnce() -> Self + UnwindSafe) -> Self {
LAST_RESULT.with(|last_result| {
{
*last_result.borrow_mut() = None;
}
match catch_unwind(f) {
Ok(flare_result) => {
let extract_err = || flare_result.as_err().map(Into::into);
// Always set the last result so it matches what's returned.
// This `Ok` branch doesn't necessarily mean the result is ok,
// only that there wasn't a panic.
last_result
.borrow_mut()
.map_mut(|last_result| {
last_result.value = flare_result;
last_result.err.or_else_mut(extract_err);
})
.get_or_insert_with(|| LastResult {
value: flare_result,
err: extract_err(),
})
.value
}
Err(e) => {
let extract_panic =
|| error::extract_panic(&e)
.map(|s| format!("internal panic with '{}'", s));
// Set the last error to the panic message if it's not already set
last_result
.borrow_mut()
.map_mut(|last_result| {
last_result.err.or_else_mut(extract_panic);
})
.get_or_insert_with(|| LastResult {
value: FlareResult::InternalError,
err: extract_panic(),
})
.value
}
}
})
}
/** Access the last result returned on the calling thread. */
fn with_last_result<R>(f: impl Fn(Option<(FlareResult, Option<&str>)>) -> R) -> R {
LAST_RESULT.with(|last_result| {
let last_result = last_result.borrow();
let last_result = last_result.as_ref().map(|last_result| {
let msg = last_result.err.as_ref().map(|msg| msg.as_ref());
(last_result.value, msg)
});
f(last_result)
})
}
}
The map_mut and or_else_mut methods are defined in an extension trait on Option that I introduced in a previous post.
FlareResult also implements the Try trait so FFI functions can use the ? operator to early return errors:
/**
Map error types that are convertible into the top-level `FlareError` into `FlareResult`s.
This is so we can use `?` on `Result<T, E: Into<error::FlareError>>` in FFI functions.
The error state will be serialized and stored in a thread-local that can be queried later.
*/
impl<E> From<E> for FlareResult
where
E: Into<error::FlareError> + Fail,
{
fn from(e: E) -> Self {
// Get a formatted string representing the error
// This includes its chain of causes
let err = Some(error::format(&e));
// Convert the error into a top-level `FlareError`
// This can then be converted into an FFI-specific `FlareResult`
let flare_result = e.into().into_flare_result();
LAST_RESULT.with(|last_result| {
*last_result.borrow_mut() = Some(LastResult {
value: flare_result,
err,
});
});
flare_result
}
}
/** Allow carrying standard `Result`s as `FlareResult`s. */
impl Try for FlareResult {
type Ok = Self;
type Error = Self;
fn into_result(self) -> Result<Self::Ok, Self::Error> {
match self {
FlareResult::Ok | FlareResult::Done => Ok(self),
_ => Err(self),
}
}
fn from_error(result: Self::Error) -> Self {
if result.as_err().is_none() {
panic!(format!(
"attempted to return success code `{:?}` as an error",
result
));
}
result
}
fn from_ok(result: Self::Ok) -> Self {
if result.as_err().is_some() {
panic!(format!(
"attempted to return error code `{:?}` as success",
result
));
}
result
}
}
FlareResult makes it much nicer to write FFI functions more idiomatically and have error information captured or consumers across the boundary.
In C#
The C# implementation of FlareResult wraps the error codes internally and exposes a higher-level API that we can use to determine how to proceed after making an FFI call. It looks like this:
[StructLayout(LayoutKind.Sequential)]
public struct FlareResult
{
enum FlareResultValue : uint
{
Ok,
Done,
BufferTooSmall,
ArgumentNull,
InternalError,
..
}
readonly FlareResultValue _result;
public static (FlareResult, string) GetLastResult()
{
return LastResult.GetLastResult();
}
// Check the native result for an error
// If there is one, we capture it and wrap it in a .NET exception
public void EnsureSuccess()
{
if (IsSuccess()) return;
var (lastResult, msg) = GetLastResult();
// This isn't perfect, but avoids some cases where native calls are made
// between checking for success.
if (lastResult._result == _result)
{
throw new Exception($"Flare failed with {_result}: {msg?.TrimEnd()}");
}
throw new Exception($"Flare failed with {_result}");
}
public bool IsSuccess()
{
return _result == FlareResultValue.Ok || _result == FlareResultValue.Done;
}
public bool IsDone()
{
return _result == FlareResultValue.Done;
}
public bool IsBufferTooSmall()
{
return _result == FlareResultValue.BufferTooSmall;
}
}
Bindings
The raw bindings are a set of functions with a C calling convention exported by the Rust library, and imported by the .NET runtime.
In Rust
To simplify safety checks in the FFI binding functions, we use a macro to declare our bindings in Rust called ffi!. Macros are like compile-time functions that operate on fragments of syntax to generate code. The ffi! macro takes care of ensuring arguments aren't null and capturing panics and other errors so they can be consumed by the foreign caller.
Before looking at the definition of the macro itself, let's see how it's used. This is what our FFI bindings for the read API look like using the ffi! macro:
ffi! {
fn flare_read_begin(
store: FlareStoreHandle,
range: *const FlareRange,
direction: FlareOrdering,
reader: Out<FlareReaderHandle>
) -> FlareResult {
let range = &*range;
let index_expr = range.index_expr()?;
let direction = match direction {
FlareOrdering::Ascending => Direction::Causal,
FlareOrdering::Descending => Direction::Anticausal,
};
let range = range.range();
let vread = store.inner.begin_read(range, index_expr, direction)?;
*reader = FlareReaderHandle::alloc(FlareReader {
inner: vread
});
FlareResult::Ok
}
fn flare_read_next(
reader: FlareReaderHandle,
key: Out<FlareKey>,
value_buf: *mut u8,
value_buf_len: size_t,
actual_value_len: Out<size_t>
) -> FlareResult {
fn call_read(
vreader: &mut FlareReader,
buf: &mut [u8],
key: &mut FlareKey,
actual_value_len: &mut usize
) -> FlareResult {
let reader = &mut vreader.inner;
// Read the current event into the caller-supplied buffer
// We early return from this function if the buffer is too small
let read_result = reader.with_current(|current|
stream_read::into_fixed_buffer(current, buf, key, actual_value_len))?;
match read_result {
Some(result) => {
// If the result is ok then we're done with this event
// Fetch the next one
if let FlareResult::Ok = result {
reader.move_next()?;
}
result
}
// If there is no result then we don't have an event
// Fetch the next event and recurse
None => {
if reader.move_next()? {
call_read(vreader, buf, key, actual_value_len)
} else {
FlareResult::Done
}
}
}
}
let buf = slice::from_raw_parts_mut(value_buf, value_buf_len);
call_read(&mut reader, buf, &mut *key, &mut *actual_value_len)
}
fn flare_read_end(reader: FlareReaderHandle) -> FlareResult {
FlareReaderHandle::dealloc(reader, |r| {
r.inner.complete()?;
FlareResult::Ok
})
}
}
Most of the work here is in the flare_read_next function, which attempts to read an event into a caller-supplied buffer and return an appropriate error code if it doesn't fit. The StoreReader type it works with has a similar to API to the streaming_iterator::StreamingIterator trait. We saw the C# counterpart to the flare_read_next function in the Reader.TryReadNext method.
The Out type is a simple type alias that makes it clear that we expect the function to assign to that argument:
type Out<T> = *mut T;
Now let's take a look at the ffi! macro itself and see what it does.
Using macros to build safer bindings
The flare_read_begin, flare_read_next, and flare_read_end functions are expanded by the ffi! macro to include boilerplate for ensuring arguments aren't null and to catch any panics using the FlareResult type we saw earlier.
The ffi! macro itself looks like this (don't worry if the syntax looks unfamiliar, Rust macros are a bit different from regular Rust code):
macro_rules! ffi {
($(fn $name:ident($($arg_ident:ident: $arg_ty:ty),*) -> FlareResult $body:expr)*) => {
$(
#[no_mangle]
pub unsafe extern "C" fn $name( $($arg_ident : $arg_ty),* ) -> FlareResult {
#[allow(unused_mut)]
unsafe fn call( $(mut $arg_ident: $arg_ty),* ) -> FlareResult {
if $($arg_ident.is_null()) || * {
return FlareResult::ArgumentNull;
}
$body
}
FlareResult::catch(move || call( $($arg_ident),* ))
}
)*
};
}
Argument null checking is handled by a trait called IsNull. This trait is fairly simple and we only implement it for argument types that are used in the FFI bindings:
/**
Whether or not a value passed across an FFI boundary is null.
*/
pub(super) trait IsNull {
fn is_null(&self) -> bool;
}
impl<T: ?Sized> IsNull for *const T {
fn is_null(&self) -> bool {
<*const T>::is_null(*self)
}
}
impl<T: ?Sized> IsNull for *mut T {
fn is_null(&self) -> bool {
<*mut T>::is_null(*self)
}
}
impl<T: ?Sized> IsNull for super::HandleOwned<T> {
fn is_null(&self) -> bool {
self.0.is_null()
}
}
impl<T: ?Sized + Sync> IsNull for super::HandleShared<T> {
fn is_null(&self) -> bool {
self.0.is_null()
}
}
macro_rules! never_null {
($($t:ty),*) => {
$(
impl IsNull for $t {
fn is_null(&self) -> bool { false }
}
)*
}
}
// Values that aren't pointers aren't ever considered null
never_null!(
usize,
isize,
u8,
u16,
u32,
u64,
u128,
i8,
i16,
i32,
i64,
i128,
bool,
super::FlareOrdering
);
The magic is in the ffi! macro, that knows what all the arguments to the function are and can automatically call IsNull::is_null on each of them.
In C#
There's a standard tool for importing unmanaged function bindings in .NET called P/Invoke. This feature comes with a runtime cost whenever one of the binding functions is invoked, but can be fairly cheap if you amortize the cost by doing as much work as possible in a single call, and are careful about only marshaling blittable types. A type is blittable if its values have the same in-memory representation for both managed and unmanaged code. A few examples of blittable types in .NET are int, IntPtr, and structs with only blittable fields.
The C# bindings for the three Rust functions needed to read events look like this:
static class Bindings
{
#if WINDOWS
const string NativeLib = "Native/flare";
#else
const string NativeLib = "Native/libflare";
#endif
[DllImport(NativeLib, EntryPoint = "flare_read_begin", ExactSpelling = true)]
public static extern FlareResult flare_read_begin(
StoreHandle store,
IntPtr range,
Ordering ordering,
out ReaderHandle reader);
[DllImport(NativeLib, EntryPoint = "flare_read_next", ExactSpelling = true)]
public static extern FlareResult flare_read_next(
ReaderHandle reader,
out Key key,
IntPtr valueBuf,
UIntPtr valueBufLen,
out UIntPtr actualValueLen);
[DllImport(NativeLib, EntryPoint = "flare_read_end", ExactSpelling = true)]
public static extern FlareResult flare_read_end(IntPtr reader);
}
The WINDOWS variable is a build-time constant we use for platform-specific code blocks.
The end result
That's been a whirlwind tour of how we do FFI between Rust and C# in Seq! I hope there's something in there you've found interesting. We've tried to keep the source on either side of the Rust/C# FFI boundary idiomatic. Macros on the Rust side let us reduce a lot of boilerplate when defining the C ABI. Handles on the C# side take care of the subtleties of holding unmanaged resources alongside GC-managed ones. Using an FFI-specific result type lets us combine Rust errors with .NET exceptions so we have visibility into native code. The end result is an integrated, but independent set of codebases that are idiomatic within their target domains.